Depth as Successive Coarse-Graining in Plain MLPs

Summary
A mathematical framework showing that deep neural networks implement successive coarse-graining, where each layer preserves task-relevant information while discarding irrelevant nuisance information — analogous to renormalization group flow in physics.
Links
BibTeX tap to expand
@article{dehghani2025depth,
title={Depth as Successive Coarse-Graining in Plain MLPs: An Information-Theoretic Treatment},
author={Dehghani, Nima},
year={2025},
journal={Preprint}
}
Code & Data
The room
Abstract
xyz
Overview
This work provides a mathematical framework for understanding deep neural networks through the lens of renormalization group (RG) theory from physics. The central insight is that depth implements successive coarse-graining: each layer preserves task-relevant information while systematically discarding irrelevant “nuisance” information.
Formally, this is analogous to RG flow in statistical physics, where successive transformations integrate out short-distance degrees of freedom to reveal effective long-distance behavior. The theory establishes that depth provides a qualitatively different computational strategy — not merely additional parameters, but a structured information-processing pipeline that separates signal from noise across scales.
Quick start
git clone https://github.com/neurovium/depth-coarse-graining.git
cd depth-coarse-graining
pip install -r requirements.txt
python run_experiments.py --config configs/default.yaml
Repository layout
depth-coarse-graining/
├── configs/ # experiment configurations (YAML)
├── src/
│ ├── models/ # plain MLP definitions
│ ├── info/ # mutual information estimators
│ └── rg/ # coarse-graining analysis
├── notebooks/ # figure-generating notebooks
├── run_experiments.py
└── requirements.txt
Citing
If you use this code or build on these ideas, please cite the paper using the BibTeX entry above.
Doors · concepts in this room
Related rooms
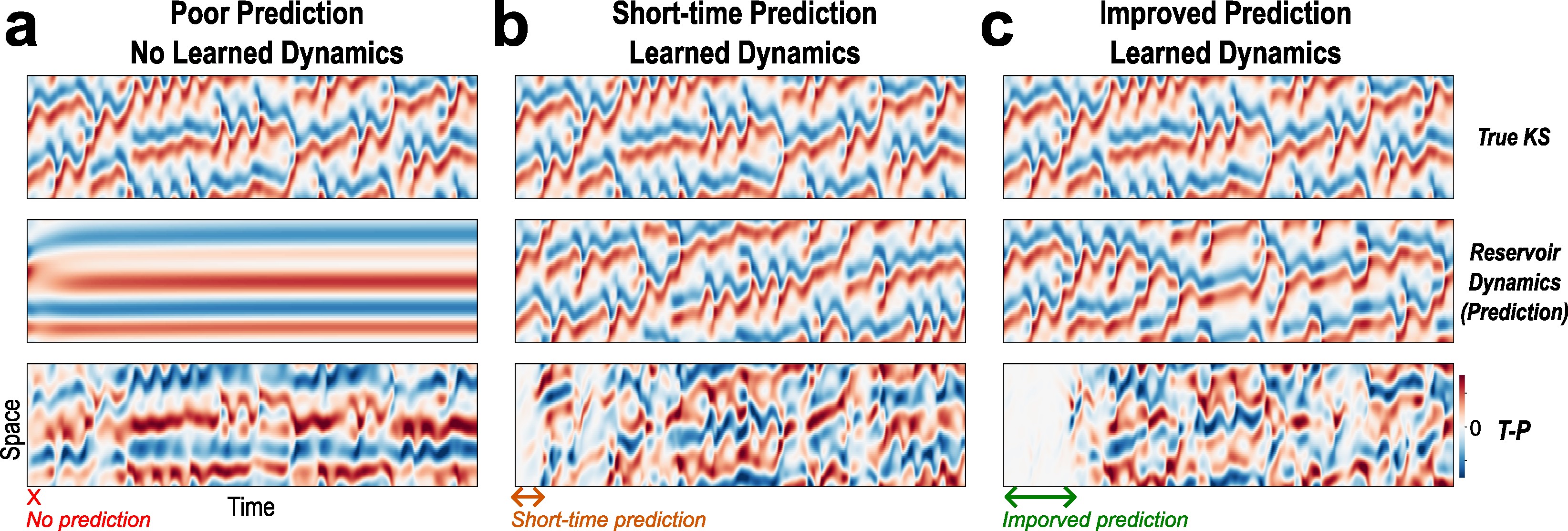
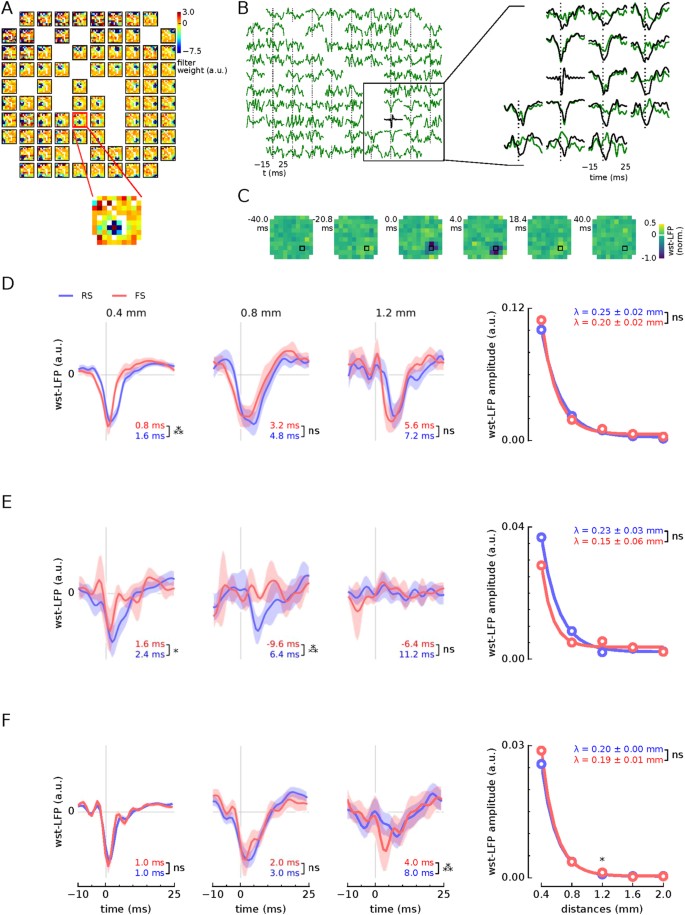
Evolutionary Optimization Reveals Structural Constraints on Reservoir Architecture for Spatiotemporal Chaos
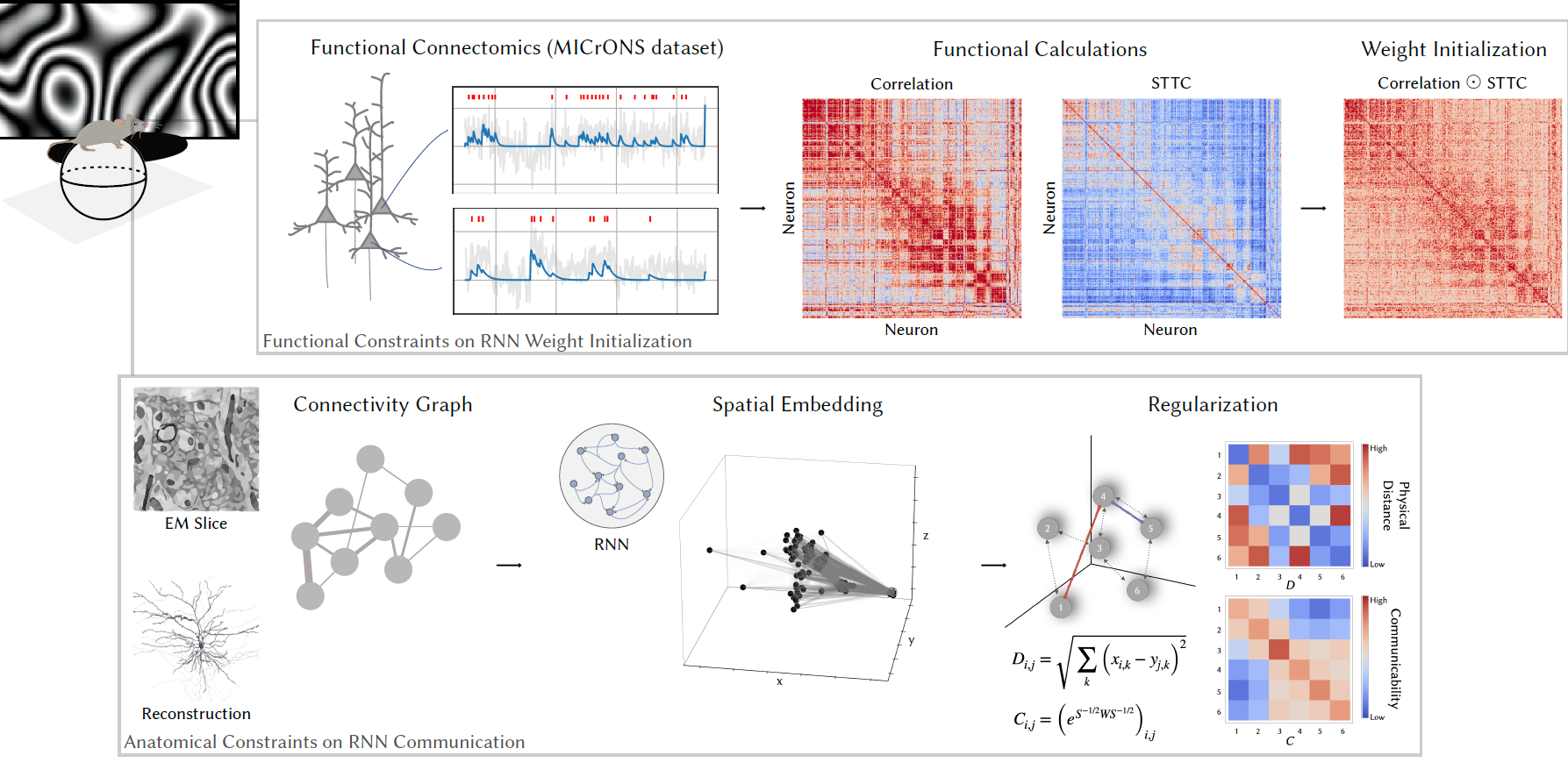
Harnessing cortical geometry, wiring, and function as inductive biases for recurrent neural networks